



-
科研进展 | 我校沈晓宇团队多项成果被国际顶级会议EMNLP接收
最新新闻 | 2024-10-11近日,EMNLP 2024(Empirical Methods in Natural Language Processing)论文录用结果公布,我校信息科学与技术学部沈晓宇团队7篇论文被 EMNLP 2024 录用。
EMNLP 是人工智能和自然语言处理领域的顶级国际会议,在相关领域享有较高的学术声誉,其涉及领域包括但不限于机器翻译、文本生成、文本分类、信息抽取、问答系统、语言模型等研究方向。该会议计划于2024年11月12日至11月16日在美国佛罗里达州迈阿密召开。
Fine-Tuning Large Language Models to Translate: Will a Touch of Noisy Data in Misaligned Languages Suffice?
作者:Dawei Zhu, Pinzhen Chen, Miaoran Zhang, Barry Haddow, Xiaoyu Shen, Dietrich Klakow
论文地址:https://arxiv.org/pdf/2404.14122
代码:https://github.com/uds-lsv/mt-sft
论文简介:传统上,多语言机器翻译的成功归因于训练数据的三个关键因素:大规模数据量、多样化的翻译方向以及高质量的数据。在当前微调大语言模型(LLMs)以进行翻译的实践中,我们重新审视了这些因素的重要性。我们发现,LLMs 在仅微调 32 对平行句子的情况下就表现出了强大的翻译能力,并且微调单一翻译方向能够实现多方向的翻译。然而,方向的选择至关重要:仅使用英文作为目标语言进行微调可能导致任务误解,从而阻碍向非英语语言的翻译。当噪声合成数据作为目标语言时,特别是当目标语言在 LLM 预训练中已得到良好表示的情况下,也会出现问题。然而,值得注意的是,合成数据对一个在预训练中代表性较低的语言的影响较为轻微。我们的研究结果表明,在将 LLMs 适配于翻译任务时,对数据量的要求可以适当放宽,但仍需仔细考虑,以防止 LLM 利用非预期的数据偏差。
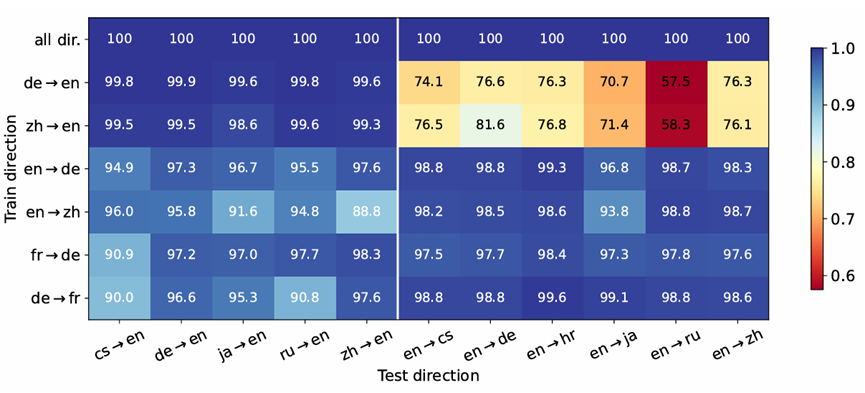
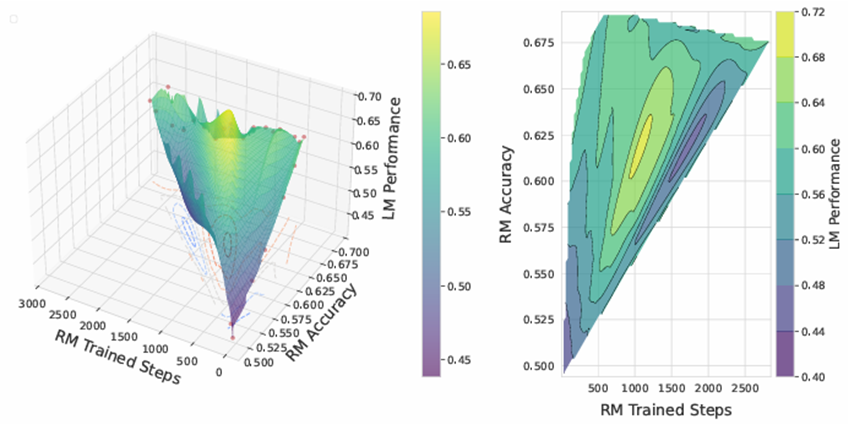
The Accuracy Paradox in RLHF: When Better Reward Models Don't Yield Better Language Models
作者:Yanjun Chen, Dawei Zhu, Yirong Sun, Xinghao Chen, Wei Zhang, Xiaoyu Shen
论文地址:https://arxiv.org/abs/2410.06554
代码:https://github.com/EIT-NLP/AccuracyParadox-RLHF
论文简介:人类反馈强化学习显著提升了自然语言处理的效果,通过训练使语言模型更符合人类预期。在这一过程中,奖励模型的强度是关键因素之一。本研究探讨了更强的奖励模型是否必然导致更优的语言模型表现。本文通过使用QA-FEEDBACK数据集和基于Longformer的奖励模型,针对相关性、事实性和完整性任务进行实验,揭示了一个令人惊讶的悖论:训练时使用中等准确率奖励模型的语言模型表现优于那些使用高准确率奖励模型的语言模型。这一发现挑战了普遍认为更强的奖励模型总是带来更好语言模型表现的观点,同时为未来关于影响模型表现的关键因素及如何选择合适奖励模型的研究开辟了新方向。
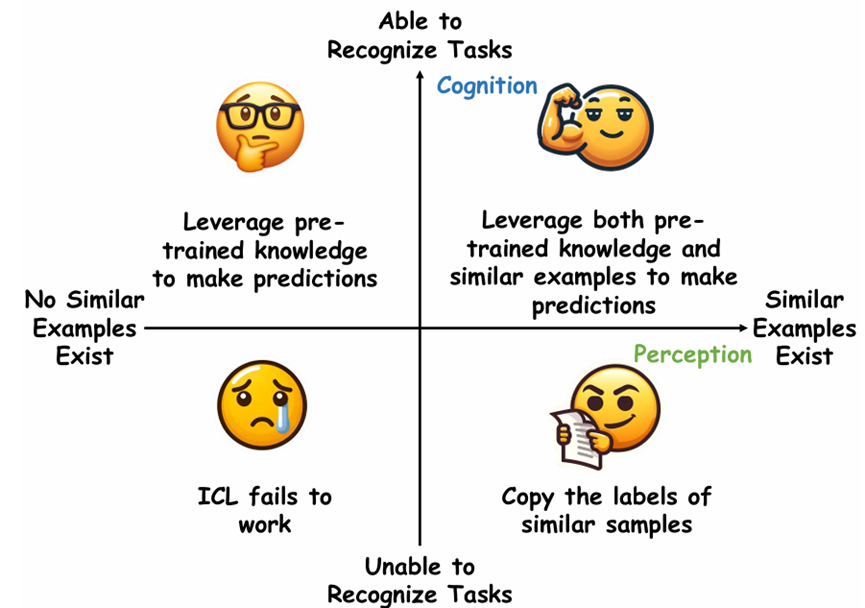
Unveiling In-Context Learning: A Coordinate System to Understand Its Working Mechanism
作者:Anhao Zhao, Fanghua Ye, Jinlan Fu, Xiaoyu Shen
论文地址:https://arxiv.org/pdf/2407.17011
代码:https://github.com/EIT-NLP/2D-Coordinate-System-for-ICL
论文简介:大型语言模型(LLMs)展现了显著的上下文学习(ICL)能力,然而其背后的工作机制仍未被充分理解。现有研究对ICL提出了两种相互矛盾的观点:一种强调演示中相似样本的重要性,指出标签正确性和更多示例的重要性;另一种则将ICL归因于LLM固有的任务识别能力,认为标签正确性和示例数量并非关键。在本研究中,我们提出了一个二维坐标系统,将这两种观点统一在一个系统框架中。该框架通过两个正交变量解释ICL的行为:演示中是否包含相似样本(感知)以及LLMs是否能够识别任务(认知)。我们提出了峰值逆序排名指标,用于检测LLMs的任务识别能力,并研究了LLMs对不同相似性定义的反应。基于此,我们进行了广泛的实验,以阐明ICL在多个代表性分类任务中的表现。最后,我们将分析扩展到生成任务,表明该坐标系统同样可以有效解释ICL在生成任务中的工作机制。
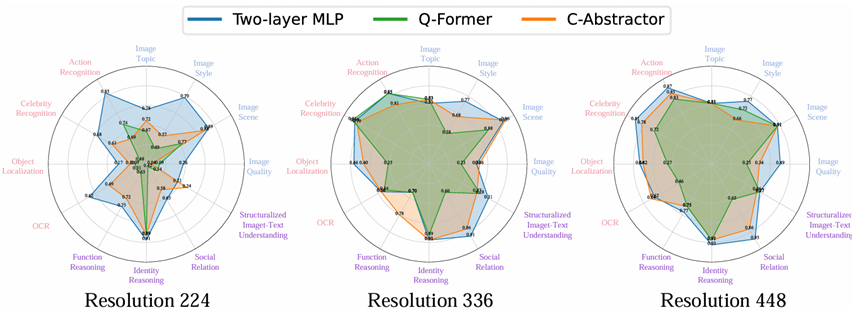
To Preserve or To Compress: An In-Depth Study of Connector Selection in Multimodal Large Language Models
作者:Junyan Lin, Haoran Chen, Dawei Zhu, Xiaoyu Shen
论文地址:http://arxiv.org/abs/2410.06765
代码:https://github.com/EIT-NLP/Connector-Selection-for-MLLM
论文简介:近年来,多模态大型语言模型(MLLMs)引起了产业界和学术界的广泛关注。根据融合位置的不同,MLLMs可分为外部融合和内部融合架构,其中外部融合架构占主导地位。然而,关于如何构建最优的外部融合MLLM架构,尤其是不同连接器在不同粒度任务中的表现,仍存在较大争议。本文系统地探讨了连接器对MLLM性能的影响。具体而言,我们将连接器分为保留特征型和压缩特征型两类。通过统一的分类标准,我们将来自三个综合基准数据集(MMBench、MME、SEED-Bench)的子任务划分为粗粒度感知、细粒度感知和推理三种任务类型,并从此角度评估连接器的性能。研究结果显示,在不同任务中,不同类型连接器的性能差异显著,这为MLLM架构设计提供了重要指导,并推动了MLLM架构优化的理解和发展。
Deeper Insights Without Updates: The Power of In-Context Learning Over Fine-Tuning
作者:Qingyu Yin, Xuzheng He, Luoao Deng, Chak Tou Leong, Fan Wang, Yanzhao Yan, Xiaoyu Shen, Qiang Zhang
论文地址:https://arxiv.org/abs/2410.04691
代码:https://github.com/MikaStars39/ICLvsFinetune
论文简介:微调和上下文学习(ICL)是两种常用的为大型语言模型注入任务特定知识的方法。通常认为,微调由于可以基于训练数据调整模型的内部参数,在有足够样本的情况下会优于ICL。然而,本文提出了一个反直觉的发现:对于隐式模式任务,ICL能够显著优于微调捕捉这些模式。我们构建了多个包含隐式模式的数据集,例如通过奇偶性确定答案的序列或在计算中识别可约项。然后,我们在参数规模从0.5B到7B的模型上,分别评估了在微调和ICL条件下模型对这些模式的理解。结果表明,采用ICL的模型可以快速掌握深层模式,并显著提高准确性。相反,尽管微调使用了比ICL多数千倍的训练样本,但其性能提升有限。我们还从机械可解释性的角度提出了电路迁移理论,解释了为何ICL在这类任务上表现更好。
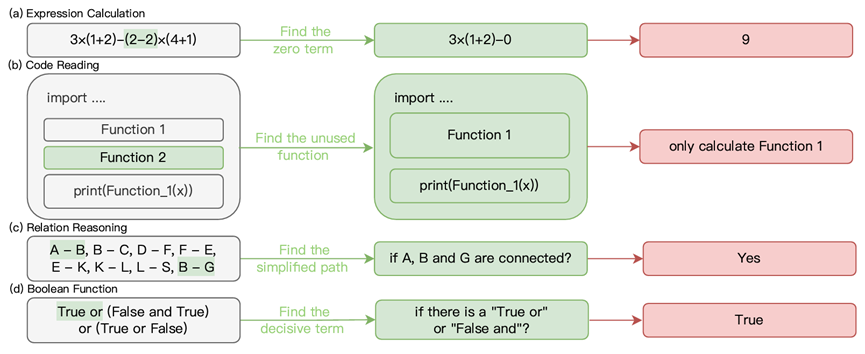
LawBench: Benchmarking Legal Knowledge of Large Language Models
作者:Zhiwei Fei,Xiaoyu Shen,Dawei Zhu,Fengzhe Zhou,Zhuo Han,Alan Huang,Songyang Zhang,Kai Chen,Zhixin Yin,Zongwen Shen,Jidong Ge,Vincent Ng
论文地址:https://arxiv.org/pdf/2309.16289
代码:https://github.com/open-compass/LawBench/
论文简介:我们提出了LawBench,这是第一个由20个任务组成的评估基准,旨在评估大型语言模型(LLMs)在处理中文法律相关任务中的表现。LawBench经过精心设计,能够从广泛接受的布卢姆认知分类法对应的三个认知层次上,精确评估LLMs的法律能力。利用LawBench,我们对21个热门LLMs进行了全面的评估,并首次对其实际表现进行了比较分析,揭示了它们的相对优势与劣势。所有数据、模型预测和评估代码均可从https://github.com/open-compass/LawBench获取。
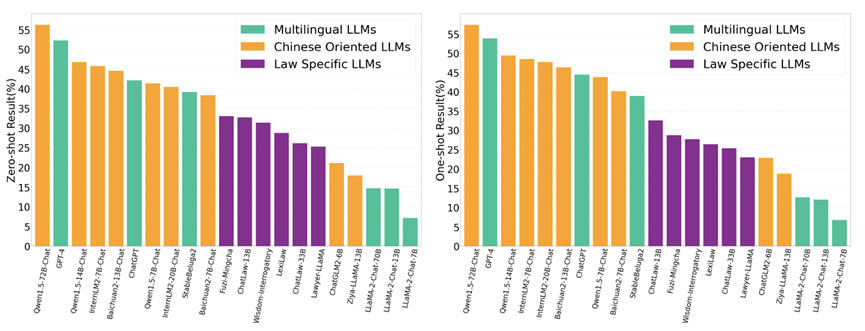
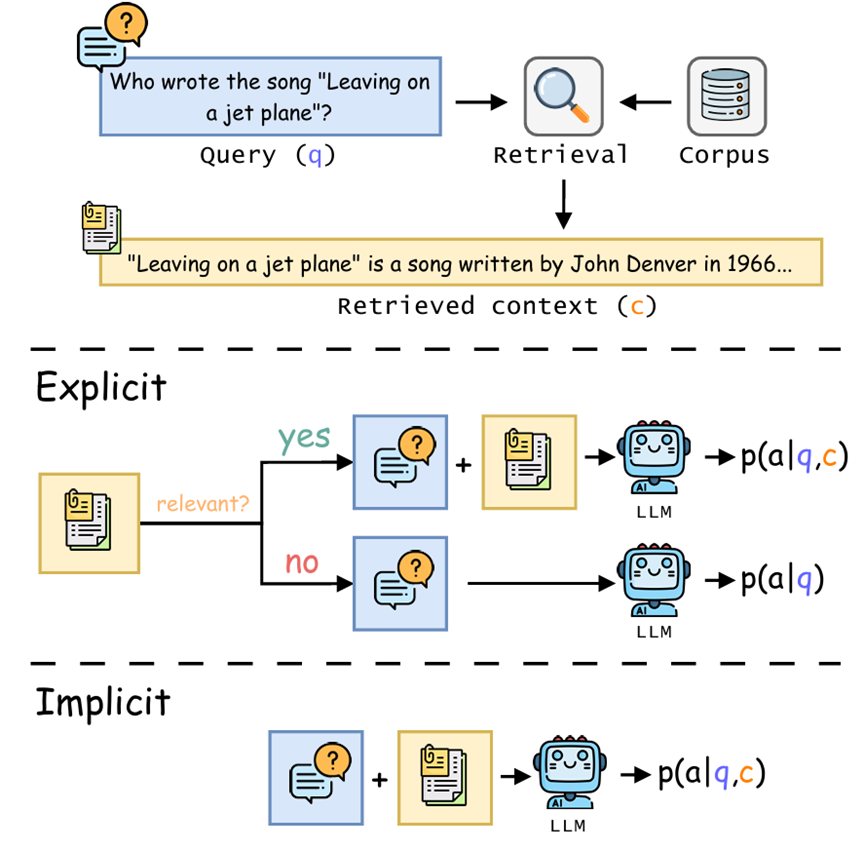
Assessing “Implicit” Retrieval Robustness of Large Language Models
作者:Xiaoyu Shen, Rexhina Blloshmi, Dawei Zhu, Jiahuan Pei, Wei Zhang
论文地址:https://arxiv.org/pdf/2406.18134
论文简介:检索增强生成(Retrieval-augmented generation,RAG)作为一种通过外部知识增强大型语言模型的框架,近年来备受关注。然而,其有效性在很大程度上依赖于模型的检索稳健性。如果模型缺乏检索稳健性,其性能将受限于检索器的准确性,当检索到的上下文与任务无关时,模型表现可能大幅下降。在本文中,我们评估了不同大型语言模型的“隐式”检索稳健性,要求它们直接输出最终答案,而不显式判断检索到的上下文的相关性。我们的研究表明,混合使用真实数据和干扰上下文进行微调,能够显著增强模型应对检索不准确的稳健性,同时在检索准确时仍能提取正确答案。这表明,大型语言模型可以通过仅从最终答案的监督中学习,以端到端的方式隐式处理相关或不相关的检索上下文。引入显式相关性判断的过程可能是不必要的,反而会破坏端到端方法的流畅性。
招生招聘
实验室长期招聘具有人工智能、自然语言处理、多模态对齐等相关专业背景的优秀博士生、博士后、研究序列人员(RAP)、工程师序列人员、实习生,欢迎加入。
联系人:沈晓宇(xyshen@eitech.edu.cn)
实验室NLP小组主页:https://eit-nlp.github.io/
_______________________________________________________________________________
